A canary deployment strategy is all about releasing new software versions safely. Instead of pushing an update out to everyone at once, you first roll it out to a small, controlled group of users your “canaries”. This lets you test the new version with real traffic in a live production environment, drastically reducing the risk of a major failure. It’s how modern teams ship software with confidence.
Why Adopt a Canary Deployment Strategy?

Let’s move past the theory. Top engineering teams rely on canary deployments because they are a powerful tool for risk mitigation. Think of it as a safety net for your releases. Rather than the old “big bang” approach where everyone gets the new version simultaneously, you introduce it gradually. This small segment of users acts as an early warning system, much like the canaries once used in coal mines to detect toxic gases.
If this initial group runs into errors, performance slowdowns, or any other strange behaviour, you’ve successfully contained the problem. The “blast radius” is tiny, impacting only a fraction of your user base. This gives you the breathing room to roll back the changes quickly without causing a widespread outage or ruining the experience for all your users.
Reducing Risk and Minimising Downtime
The real magic of a canary deployment is how it de-risks the entire release process. No matter how much you test, every new release carries some uncertainty. A canary strategy accepts this and builds a smart process around it, allowing you to catch bugs in a real-world setting where automated tests might have missed them.
This staged rollout is fundamental to achieving seamless updates. As we discuss in our guide on [https://signiance.com/zero-downtime-deployment/], strategies like this work together to keep your application available and responsive, even while you’re deploying new code. By ditching the all-or-nothing approach, you protect your users and your team’s sanity.
In the Indian tech scene, for instance, this strategy is crucial for safer software releases. A common approach is to route a small slice of live traffic often starting at just 5% to the new version. This helps engineers spot issues like latency spikes or rising error rates immediately, allowing for an instant rollback with minimal disruption. Further traffic increases are only approved if performance metrics hold steady, ensuring business goals aren’t compromised during the rollout.
Comparing Core Deployment Strategies
While effective, canary deployment isn’t your only option. It’s often evaluated alongside blue-green deployments and rolling updates, each with its own strengths and weaknesses. Understanding the trade-offs is key to picking the right strategy for your needs.
Here’s a quick comparison to see how they stack up.
| Attribute | Canary Deployment | Blue-Green Deployment | Rolling Update |
|---|---|---|---|
| Risk Exposure | Very low; affects a small user subset initially. | Low; instant switch, but all users are affected at once. | Medium; nodes are updated sequentially. |
| Cost | Can be higher due to running parallel versions. | High; requires duplicate infrastructure. | Low; no extra infrastructure is needed. |
| Downtime | None; traffic is shifted seamlessly. | None; traffic is switched via a router. | None; active nodes handle traffic. |
| Feedback Quality | Excellent; real user data on new and old versions. | Limited; no parallel run for comparison. | Good; can monitor nodes as they update. |
Ultimately, each strategy has its place. Rolling updates are simple and cheap, while blue-green offers a fast and clean cutover.
Key Takeaway: A canary deployment truly shines for high-stakes, complex applications where user experience and stability are non-negotiable. It provides the most control and the richest data for making an informed go/no-go decision on a new release.
Designing Your Canary-Ready Architecture

You can’t just flip a switch and “do” a canary deployment. A successful canary strategy is something you bake right into your application’s architecture from the ground up. Before you can even think about rolling out a new version, your systems must be designed for incredibly precise traffic control. At its core, this means having the right infrastructure in place to intelligently route users between the old, stable version and the new one you’re testing.
The absolute cornerstone of this setup is your traffic splitting mechanism. You need a way to siphon off a small, specific percentage of user requests and direct them to the canary instance, while everyone else continues to use the proven, stable version. This is where tools like advanced load balancers, API gateways, and service meshes really shine.
Core Components for Traffic Control
The tools you pick will directly influence how sophisticated your canary strategy can be. While there are a lot of options out there, they generally fall into a few key categories, each with its own trade-offs in terms of control and complexity.
- Advanced Load Balancers: For many teams, modern cloud load balancers are the most straightforward entry point. An AWS Application Load Balancer (ALB), for example, supports weighted target groups out of the box. This lets you configure a simple rule to send, say, 95% of traffic to your stable version and the remaining 5% to the new canary.
- API Gateways: If you’re running an API-driven architecture, a gateway like Amazon API Gateway or Kong is a natural fit for managing this traffic split. This approach is particularly powerful in a microservices setup where you might be updating individual services at different cadences.
- Service Meshes: When you need the absolute finest-grained control, a service mesh like Istio or Linkerd is the gold standard. A service mesh sits at a layer below your application code, giving you powerful tools to route traffic based on things like HTTP headers, user location, or even specific cookies. This enables some seriously targeted and advanced canary testing.
Honestly, for most teams just getting started, an AWS ALB is a fantastic and practical first step. It gives you robust, percentage-based traffic splitting without the heavy operational lift of managing a full service mesh. You can always evolve to a more complex solution as your needs grow.
A Practical Example with AWS ALB
Let’s walk through a common real-world scenario. Imagine you have a web app running on Amazon EC2 instances or in ECS containers. Your current, stable version (v1.0) is handling 100% of the traffic, and you’re ready to test out version v1.1.
To get this canary release off the ground, you’d set up two distinct target groups in your ALB.
- Stable Target Group: This group points to all the instances running v1.0 of your app.
- Canary Target Group: This one points to the new instances you’ve spun up with v1.1.
From there, you configure a listener rule on your ALB to use weighted forwarding. You might start cautiously, setting the weights so the stable target group gets 98% of the traffic, while the new canary target group receives just 2%. The ALB handles the rest, automatically distributing requests according to those weights. Just like that, you’ve seamlessly introduced your new code to a small slice of real users.
Managing State and Database Schema
Architecting for canaries isn’t just about routing requests; one of the biggest hurdles you’ll face is managing state, especially when it comes to your database. During the canary deployment, both the old and new versions of your application are live, running side-by-side, and often hitting the same database. This can get tricky.
Critical Consideration: Your database schema must be backward-compatible. The new application version (v1.1) might introduce new columns or even tables, but it absolutely must read and write data in a way that the old version (v1.0) can still understand.
If you introduce a breaking change, like renaming or deleting a column that v1.0 depends on, you’re going to see failures almost immediately. This often means you need a multi-step release process. First, you deploy the backward-compatible schema change. Once that’s settled, you can deploy the new application code that uses it. The exact same principle applies to any other stateful service in your stack, like caching layers or message queues, to ensure both versions can coexist peacefully without corrupting data.
Weaving Canary Releases into Your CI/CD Pipeline
Having a canary-ready architecture is one thing, but the real magic happens when you connect it directly to your Continuous Integration/Continuous Deployment (CI/CD) pipeline. This is the moment your canary deployment strategy goes from a manual, nerve-wracking exercise to a smooth, automated workflow. Let’s walk through how to embed this into your delivery process, getting from a developer’s git push to a safe, controlled production rollout with almost no one touching a keyboard.
For this guide, we’ll ground our examples in a popular and robust toolset: AWS CodePipeline, CodeBuild, and CodeDeploy. Together, they give you all the components needed to build, test, and orchestrate a phased release automatically.
Automating the Canary Flow with AWS
The aim here is a seamless, hands-off process. A developer commits their code, and the pipeline takes over. It builds the new application version, deploys it to a small slice of your infrastructure, runs automated health checks, and then only if all is well gradually shifts more traffic over. This automation is the secret sauce for moving fast without breaking things.
The entire system pivots on a well-configured AWS CodeDeploy deployment group. This is where you lay down the rules of engagement for your release.
- Deployment Type: You’ll start by choosing either an in-place or a blue/green deployment model.
- Traffic Shifting: This is the key. You must select a
CanaryorLineartraffic shifting option. This instructs CodeDeploy not to flip a giant switch and send 100% of traffic at once, but to follow a gradual rollout pattern that you define. - Health Checks: You can tie Amazon CloudWatch alarms directly to the deployment group. If an alarm fires during the rollout say, because of a spike in 5xx server errors CodeDeploy automatically hits the brakes and starts a rollback.
This represents a huge leap from old-school manual deployments. For a deeper dive into this concept, our guide on automated software deployment explores what it takes to build these kinds of resilient, hands-off delivery systems.
This screenshot from the AWS console shows exactly where you’d manage and keep an eye on these automated deployments.
A dashboard like this gives you a single pane of glass to see deployment successes, failures, and what’s currently in progress. You can see the health of your release pipeline at a glance.
The Power of Lifecycle Hooks
Manually checking if a canary version is healthy is slow, tedious, and ripe for human error. This is where CodeDeploy lifecycle hooks become your secret weapon. These hooks let you run custom code, usually an AWS Lambda function, at very specific moments during the deployment.
For a canary deployment, the two most critical hooks are BeforeAllowTraffic and AfterAllowTraffic.
Expert Tip: I always use the
BeforeAllowTraffichook to run a battery of integration or smoke tests against the new canary instances before a single real user sees them. Think of it as a final sanity check to catch any glaring configuration issues or show-stopping bugs right out of the gate.
Once those initial tests pass, CodeDeploy shifts the first tiny percentage of traffic maybe 10% to the canary. This is when the AfterAllowTraffic hook kicks in. Now it’s time for the real test. Your Lambda function can run a series of checks against the live canary, for instance:
- Hitting key API endpoints and verifying a
200 OKresponse. - Querying CloudWatch Metrics to make sure latency and error rates are well within your accepted limits.
- Running a synthetic transaction, like simulating a user adding an item to a shopping cart, to confirm core business logic is working.
If any of these checks fail, the Lambda function simply returns a ‘Failed’ status back to CodeDeploy. That’s the signal for an immediate, automatic rollback. What you’ve just built is a powerful, self-healing deployment system.
Defining Your Rollout Strategy
Inside CodeDeploy, you’re not stuck with a one-size-fits-all approach. You can pick from pre-built canary strategies or create your own custom one. Common built-in options include:
- Canary10Percent5Minutes: This shifts 10% of traffic, “bakes” for 5 minutes to gather data, and then moves the remaining 90%.
- Linear10PercentEvery1Minute: This gradually ramps up traffic by 10% every minute until the new version is handling 100% of requests.
- Custom Strategy: You can get really specific. For example, you could shift 5% for 15 minutes, then ramp up to 25% for another 30 minutes, and finally roll out to everyone.
Your choice really boils down to your risk tolerance and how quickly your monitoring can give you meaningful data. For a business-critical payment service, I’d recommend a slow, multi-stage rollout with long bake times. For a low-risk internal tool, a fast linear rollout is probably fine.
By wiring these tools and processes together, your canary deployment strategy stops being a theoretical concept and becomes a reliable, automated part of how you deliver software.
Mastering Traffic Analysis and Key Metrics

The real magic of a canary deployment strategy isn’t just about diverting traffic it’s about what you learn from that traffic. Watching how your new code performs under the pressure of live user interactions is the entire point of the exercise. This analysis is your go/no-go signal, telling you whether to push forward with confidence or hit the brakes and roll back to safety.
Your first decision is crucial: who gets to be the canary? You need a group large enough to provide statistically meaningful data, but small enough that a potential bug doesn’t turn into a major incident. The way you slice this audience can be simple or incredibly precise.
Choosing Your Canary Audience
The most common starting point is a straightforward percentage-based split. Using a tool like an AWS Application Load Balancer, it’s easy to route, say, 5% of your total traffic to the new version. This approach is beautifully simple and gives you a good general feel for how the new code behaves across your user base.
But sometimes, a broad approach isn’t enough. You need to be more surgical, and that’s where attribute-based routing shines. This technique, often handled by service meshes like Istio or advanced API gateways, lets you target users based on very specific characteristics.
- Geographic Location: Want to test a new feature just for users in a specific city? Attribute-based routing makes that possible, limiting the blast radius to a single time zone or region.
- User Tier: Perhaps you want to give your “premium” or “pro” users an early look. You can use an HTTP header or user token to identify and route just that segment.
- Device Type: If you’ve just rolled out a big mobile optimisation, you could route traffic only from iOS or Android devices to the canary instance.
This level of control is incredibly powerful. It allows you to test specific hypotheses with laser focus before going wide. For instance, if you’ve re-engineered your checkout flow for a new payment provider in a particular country, you can target only users from that country who are actively trying to make a purchase.
Defining Your Key Performance Indicators
Sending traffic to your canary is pointless if you don’t know what success looks like. Your decision to roll out or roll back has to be driven by data, not gut feelings. A common pitfall is obsessing over technical metrics while completely ignoring the business impact. A truly healthy release needs to satisfy both.
First, you’ll want to monitor the technical health of the service, often called the “golden signals.”
- Latency: How long are requests taking? A sudden spike in response time for the canary compared to the stable version is a massive red flag.
- Traffic: Are requests flowing at the rate you expect?
- Errors: Pay very close attention to the rate of HTTP
5xxserver errors. An uptick here almost always points to a critical bug in the new code. - Saturation: Is the canary straining your infrastructure? Keep a close watch on CPU and memory utilisation to make sure the new version isn’t a resource hog.
These metrics tell you if the application is running, but they don’t tell you if it’s working for your users. That’s where business metrics come in. These will be unique to your application but often include things like:
- Conversion Rate: Are users still signing up, making purchases, or completing key actions at the same pace?
- User Engagement: Are metrics like “items added to cart,” “articles read,” or “time on page” suddenly dropping for the canary group?
- Customer Support Tickets: A sudden flood of support queries about a new feature is a canary in the coal mine, signalling deep-seated user confusion or bugs.
The Canary Analysis Checklist
Before giving a release the green light, your team should be able to answer “yes” to these questions:
- Is the canary version’s error rate within our acceptable threshold (e.g., less than 0.1%)?
- Is the average and 95th percentile latency comparable to the stable version?
- Are core business metrics (e.g., conversions, sign-ups) performing at or above the baseline?
- Have we seen no critical exceptions or new error types in our logging platform?
- Is the resource utilisation (CPU/memory) of the canary sustainable?
This kind of checklist helps remove emotion and guesswork from the decision-making process. Interestingly, a study of Indian organisations found that about 60% of companies blend canary deployments with other strategies to create a more resilient system. This hybrid approach boasts a 93% success rate, significantly higher than the 80% seen with standalone canary use, as the extra checks add another layer of reliability. The same analysis noted that Indian startups often deploy multiple times a week to stay agile, while larger MNCs tend to favour less frequent, more stability-focused releases. You can explore more about these deployment trends in the full report on deployment practices.
Automating Rollbacks and Finalising Releases
Any deployment strategy is only as good as its safety net. Even the most meticulously planned canary can hit a snag. When that happens, your absolute priority is to contain the damage and get back to a stable state instantly. This is where automated rollbacks come in, turning your canary deployment strategy from a nice idea into a truly resilient, production-ready system.
The whole point is to take human delay out of the equation. No more panicked 3 AM calls to an on-call engineer trying to figure out what an alert means. The system should, in essence, heal itself. You achieve this by creating a tight feedback loop between your monitoring tools and your deployment orchestrator.
Triggering an Automatic Rollback
In a modern cloud setup, this usually involves setting up automated alarms on your most important health metrics. If you’re on AWS, a service like Amazon CloudWatch is your best friend here. You can configure alarms that watch the performance of your canary’s target group like a hawk.
Your job is to define what “failure” looks like in precise terms. These aren’t just vague guidelines; they are hard-and-fast rules that, if breached, signal an unacceptable drop in service quality.
- Error Rate Threshold: You might set an alarm to fire if the rate of HTTP
5xxserver errors from the canary version goes above 1% for more than five minutes. - Latency Threshold: Another critical alarm could watch the 95th percentile (p95) latency, triggering if it jumps 20% above the stable version’s established baseline.
As soon as an alarm flips into its ALARM state, it sends a signal straight to a tool like AWS CodeDeploy. CodeDeploy doesn’t hesitate it immediately halts the rollout. More importantly, it kicks off an automatic rollback, instantly shifting 100% of traffic back to the original, stable version. The faulty canary is effectively quarantined. This entire process can be over in seconds, often before most of your users even know anything was amiss.
A well-configured rollback mechanism is your ultimate safety guarantee. It ensures that even a catastrophic failure in the new code only affects a small number of users for a very brief time.
Defining these rules is critical and should be directly tied to your business objectives. A great place to start is by looking at established service level agreement templates, as they help you formalise what “good performance” actually means for your application.
Finalising a Successful Release
But what about when things go perfectly? If your canary version cruises through its observation window, meeting or even beating all performance benchmarks, it’s time to make it official. Don’t rush this part; it should be a deliberate, final checkpoint in your pipeline.
Once your team gives the go-ahead, finalising the release is a two-step dance.
- Shift 100% of Traffic: First, you’ll update your deployment configuration whether that’s in AWS CodeDeploy, your service mesh, or the load balancer to move all remaining user traffic from the old version to the new, fully-vetted canary.
- Decommission the Old Version: After letting the new version handle full traffic for a bit to ensure stability, you have to decommission the old infrastructure. This is non-negotiable housekeeping. Leaving old versions running just adds complexity, opens up potential security holes, and burns money on resources you no longer need.
This last step closes the loop on the release lifecycle. The canary has now become the new stable version, setting the stage for the next deployment. It’s this cyclical, safety-first process that makes the canary deployment strategy so incredibly powerful.
This incremental approach is proving essential in complex fields like telecommunications. The Indian telecom industry, for instance, is increasingly using specialised ‘canary rApps’ to manage upgrades to its radio access network (RAN) and cloud infrastructure. This allows them to gradually expose updates to small network segments, monitoring health indicators like latency to prevent the widespread service outages that were common with older deployment methods. Given India’s massive and growing demand for high network availability, this strategy has been shown to significantly reduce service interruptions. You can read more about these telecom deployment advancements on networkblog.global.fujitsu.com.
Common Questions About Canary Deployments
Even with the best-laid plans, actually putting a new deployment strategy into practice always brings up some real-world questions. A canary deployment is a powerful technique, but it’s normal for teams to run into a few common sticking points the first few times around. Let’s dig into some of the questions I hear most often to help you smooth out the bumps.
Getting the details right here is crucial. A small misstep in traffic allocation or a blind spot in your monitoring can quickly negate the safety net you’re trying to build.
How Much Traffic Should I Send to the Canary?
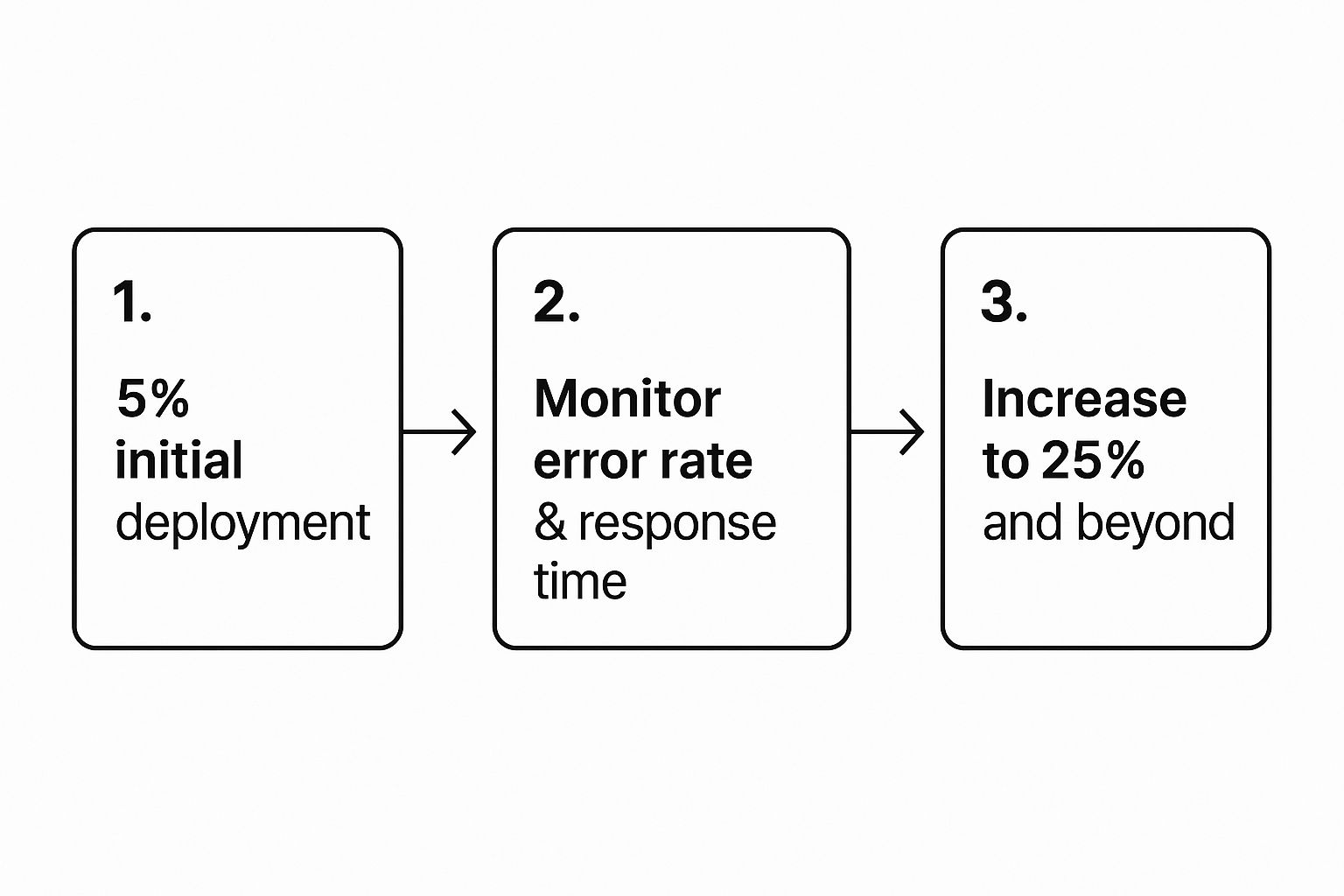
There isn’t a single magic number that works for everyone, but a good, conservative starting point is somewhere between 1% and 5% of your total traffic. The idea is to send just enough traffic to get meaningful data on performance and errors without putting too many users at risk if something goes wrong. You need enough requests to see a clear signal through the everyday noise of your system.
Once that initial canary is looking healthy, you can start dialling up the traffic as your confidence grows. A typical progression might be something like this:
- Phase 1: 5% of traffic for 30 minutes.
- Phase 2: 25% of traffic for 1 hour.
- Phase 3: 50% of traffic for another hour.
This phased increase gives you a chance to see how the new version behaves under a bit more load before you go all in.
Do I Need a Service Mesh to Do This?
Not at all. While a service mesh like Istio or Linkerd gives you incredibly precise control over traffic, it’s definitely not a requirement for a good canary deployment. For many teams, especially when they’re just starting out, a full-blown service mesh is honestly overkill.
You can set up a perfectly solid canary workflow using tools you’re probably already using. Modern Application Load Balancers (ALBs) or API gateways are more than capable of handling it. For example, AWS Application Load Balancers have a feature called weighted target groups, which lets you send a specific percentage of traffic to different versions of your application. This is often the simplest and most direct way to get started.
What’s the Biggest Mistake Teams Make?
By far, the most common and damaging mistake is focusing only on technical metrics while completely ignoring the business side of things. It’s so easy to get tunnel vision, staring at CPU utilisation, memory usage, and HTTP error rates. These are vital, of course, but they only paint half the picture.
A release can look technically flawless zero errors, low latency but still be a total failure for the business. If that new version confuses users and tanks your conversion rate by 15%, it’s a bad release, no matter what your infrastructure dashboards say.
A proper analysis has to include Key Performance Indicators (KPIs) that actually reflect the health of your business. Always keep an eye on metrics like user sign-ups, items added to a cart, or time spent on a key page to understand the true impact of your release.
How Is This Different from Feature Flagging?
Canary deployments and feature flagging often get lumped together, but they really solve different problems and work at different layers. Think of them as complementary tools in your toolbox, not competing ones.
- Canary Deployment: This is an infrastructure-level strategy. You’re routing real user traffic to different, fully deployed versions of an entire service to test its stability and performance in the wild.
- Feature Flagging: This is an application-level technique. It lets you turn specific features or code paths on or off for certain users at runtime, all without needing a new deployment.
In fact, the best teams often use them together. A great pattern is to roll out a new service version using a canary deployment, and then, inside that new version, use feature flags to get even more granular control over who sees which specific new functions.
Ready to build a resilient, automated CI/CD pipeline that makes canary deployments effortless? The experts at Signiance Technologies can design and implement a cloud architecture that enables safer, faster releases. Learn how we can help you innovate with confidence.