At its core, DevOps configuration management is all about automating and standardising the setup of your entire digital world. It’s the practice of making sure every server, database, and application is configured in exactly the same way, every single time. This consistency gets rid of manual errors and the little inconsistencies that can cause big headaches down the line, making it a cornerstone for any reliable and scalable tech operation.
Defining Your Infrastructure Blueprint

Think of it like this: you have a master recipe for a really complex dish. Without that precise, written-down recipe, ten different chefs are going to cook ten slightly different versions. Some will add a pinch more salt, others might cook it for a few minutes too long. The results? Unpredictable and inconsistent.
That’s what DevOps configuration management does for your IT systems it’s the master recipe. It lays out the exact state you want your infrastructure to be in. We’re talking about which software packages need to be installed, their specific versions, how network ports are set up, and where every critical file should live.
This “recipe” is captured as code, typically stored in a version control system like Git. This gives you a single source of truth that both your development and operations teams can look at, trust, and improve together.
The Ever-Present Problem of Configuration Drift
Without a central system keeping everything in line, you inevitably run into configuration drift. This is the subtle but constant tendency for systems to stray from their original, intended setup over time.
Picture this: a sysadmin makes a quick, undocumented tweak on a live server to fix an urgent bug. A few months later, a developer manually updates a software library on their test machine, but not elsewhere. These small, untracked changes start to pile up. Suddenly, the “identical” servers in your cluster are anything but.
This drift is the root cause of the classic “it works on my machine” problem, where code behaves perfectly in one environment but breaks in another.
Configuration management is the antidote to drift. It works by constantly checking your systems against the master blueprint and automatically fixing anything that’s out of place. This ensures every part of your infrastructure stays in its intended, predictable state.
This is what makes the whole approach so effective. It shifts teams away from constantly putting out fires and moves them into a more controlled, proactive way of managing their systems.
Core Concepts of Configuration Management at a Glance
To really get the hang of configuration management, you need to understand a few fundamental ideas. These concepts are the building blocks that tools like Ansible, Puppet, and Chef are built on. Getting these right is about moving from old-school manual tweaks to a more robust, code-driven methodology.
| Concept | What It Means | Why It Is Important |
|---|---|---|
| Desired State | You define the final result you want for your system, not the specific steps to get there. | This makes configurations simpler and lets the tool figure out the smartest way to achieve that state. |
| Idempotency | You can run the same configuration script over and over, and it won’t change anything after the first successful run. | This guarantees predictable outcomes and stops you from accidentally breaking things by re-running automation. |
| Source of Truth | A single, central place (usually a Git repository) holds all your configuration code. It’s the final word. | This gives you a complete audit trail, makes collaboration seamless, and ensures everyone is on the same page. |
At the end of the day, adopting configuration management is about building reliability and speed directly into the foundation of your technology. When you treat your infrastructure with the same discipline you apply to your application code, you create a system that’s not just easier to manage, but also more secure, compliant, and ready to scale.
The Guiding Principles of Modern Configuration

Truly effective DevOps configuration management isn’t just about picking the right tool. It’s about embracing a mindset a set of powerful principles that transform how we think about our infrastructure. These ideas are what elevate configuration from a series of manual, error-prone tasks into a robust, automated, and scalable engineering discipline.
Once you grasp these core philosophies, you’ll be able to unlock the real power of any configuration tool you choose.
The absolute bedrock of modern configuration is the principle of Infrastructure as Code (IaC). This is a game-changing practice where you manage and provision your entire IT environment using definition files, just as you would with your application’s source code. Instead of manually clicking through a web console or running one-off commands on a server, your entire setup is documented in code.
This simple shift brings all the tried-and-tested benefits of software development into the world of operations. You can version-control your server configs, review changes with pull requests, and even run automated tests before anything touches a live system. It creates a complete history of every change, making it worlds easier to troubleshoot when something goes wrong.
Embracing the Power of Idempotency
For any automation to be reliable, it has to be built on the principle of idempotency. It sounds a bit academic, but the idea is actually quite simple: running the same configuration script over and over again should always produce the same result, without causing errors or unexpected changes.
Think of it like a light switch. Flipping the switch to ‘on’ turns the light on. If you press the ‘on’ switch again, nothing dramatic happens the light just stays on. An idempotent script works the same way. The first time it runs, it might install a piece of software or add a new user. On every run after that, it simply confirms the software is already there and the user already exists, and then moves on without making a change.
This quality is what makes automated configuration safe and predictable. It eliminates the risk of accidentally breaking systems by re-applying a configuration, ensuring that your infrastructure always converges to the desired state, regardless of its starting point.
This predictability is what allows teams to trust their automation. You can confidently schedule scripts to run on a regular basis, knowing they will only step in to fix things that have drifted out of alignment.
Shifting from How to What
Another foundational change in modern configuration is the move away from imperative commands and toward a declarative syntax. This completely re-frames how you tell your systems what to do.
- Imperative (The “How”): This is a list of step-by-step instructions. You tell the system precisely how to get to the end state: “run this command, then create this directory, then copy this file.” This approach is rigid and can easily break if any single step fails or encounters an unexpected condition.
- Declarative (The “What”): This focuses on the final outcome. You simply define what the system should look like: “ensure this package is installed, this service is running, and this file has these specific contents.” The tool is then responsible for figuring out the best way to get there.
Most modern tools like Ansible and Puppet are built around this declarative approach. It makes your configuration files far more readable, easier to maintain, and much less fragile. You just describe your destination, and let the tool handle the journey.
Maintaining a Single Source of Truth
Finally, all these principles are held together by the concept of a single source of truth. In the world of IaC, this is almost always a version control system like Git. Every configuration file, template, and script is stored in a central repository.
This practice provides enormous benefits. It gives you a complete and transparent audit trail you can see exactly who changed what, when, and why. It also encourages collaboration, as developers and operations engineers can work from the same codebase to define and improve the infrastructure.
By making a Git repository the ultimate authority on your infrastructure, you get rid of confusion and prevent undocumented changes. If a configuration isn’t in the repository, it’s not considered a valid part of the system. This discipline is absolutely essential for maintaining the integrity, security, and consistency of all your environments, from development straight through to production.
Comparing the Top Configuration Management Tools
Picking the right tool for DevOps configuration management is one of those crucial decisions that can really shape your team’s efficiency, how well you can scale, and your overall success. The market has some heavy hitters, but the “big four”Ansible, Puppet, Chef, and SaltStack each have their own philosophy and way of doing things. Just comparing a list of features won’t give you the full picture; you need to get under the hood to see what makes them tick.
We’ll dig into their different architectural styles agent-based versus agentless and look at the languages they use, which span from simple YAML to complex, Ruby-based languages. Getting a handle on these details is the key to matching a tool to your team’s skills and your project’s actual needs.
Architecture: Agent-Based vs. Agentless
The most fundamental difference between these tools is their architecture. This one distinction has a ripple effect on everything, from how hard it is to get started to how commands are sent across your infrastructure.
- Agent-Based (Puppet, Chef, SaltStack): These tools work by installing a small piece of software, or an “agent,” on every server you need to manage. A central master server talks to these agents, which then pull down the latest configurations and apply them on their own. This approach is fantastic for keeping things consistent over time in large, stable environments.
- Agentless (Ansible): Ansible is the odd one out here because it doesn’t need any agents. It communicates with your machines using standard protocols like SSH for Linux or WinRM for Windows. This makes it incredibly straightforward to set up, which is a huge plus in situations where you can’t or don’t want to install extra software.
The agentless approach is often loved for its simplicity and low overhead, making it perfect for one-off tasks and quick application deployments. On the other hand, the agent-based model provides a really robust, continuous way to enforce rules, which is ideal for big companies with strict compliance and state management needs.
Language and Learning Curve
The language a tool uses is a massive factor in how steep the learning curve is and how quickly your team can get up to speed. A simpler language means faster adoption, while a more powerful one can give you the flexibility to handle incredibly complex logic.
Ansible uses YAML (YAML Ain’t Markup Language), which is designed to be easy for humans to read. It’s relatively simple to pick up, even if you don’t have a deep programming background. The structure is all about defining tasks in straightforward “playbooks.”
Puppet has its own declarative, Ruby-like language (DSL). It’s powerful for defining the desired state of a system, but it does mean learning a specific syntax. Chef takes this a step further by using pure Ruby in a more procedural style. This gives you immense power, but it also demands that your team has solid programming skills. SaltStack strikes a nice balance, using YAML for state definitions but letting you extend its power with Python.
Choosing a tool often comes down to your team’s existing skillset. If your team is strong in Python, SaltStack is a natural fit. If they are Ruby experts, Chef offers unparalleled control. For teams with varied technical backgrounds, Ansible’s simplicity is often the fastest path to productivity.
This chart shows just how popular each of the leading configuration management tools is, with Ansible clearly out in front.
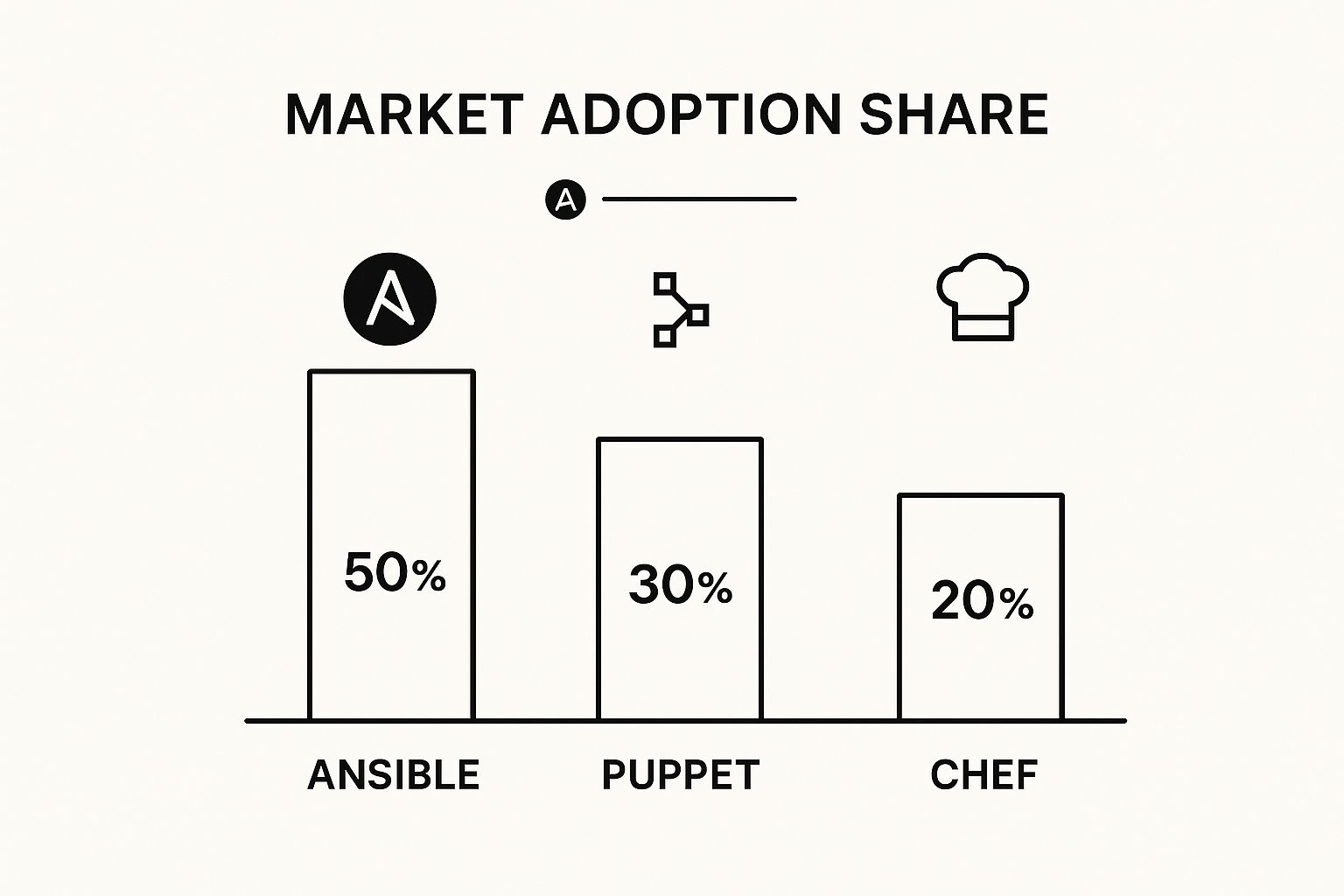
The data speaks for itself Ansible’s user-friendly nature and agentless design have made it a favourite in the DevOps community.
Ideal Use Cases and Tool Selection
The rapid move to cloud services and automation is supercharging the DevOps market. In India, for example, the growth is staggering. The Indian DevOps market was valued at USD 460.6 million in 2024 and is expected to climb to an incredible USD 2.57 billion by 2033. That’s a compound annual growth rate (CAGR) of 19.48%. This boom is driven by the urgent need for tools that help deliver software faster and more reliably.
To help you sort through the options, we’ve put together a table that breaks down the key differences between the major tools.
Ansible vs Puppet vs Chef vs SaltStack
| Tool | Architecture | Language | Learning Curve | Best For |
|---|---|---|---|---|
| Ansible | Agentless | YAML | Low | Application deployment, ad-hoc tasks, and cloud provisioning. |
| Puppet | Agent-Based | Puppet DSL (Ruby-like) | Medium | Large-scale, stable enterprise environments with strict compliance. |
| Chef | Agent-Based | Ruby DSL | High | Complex automation scenarios where development expertise is available. |
| SaltStack | Agent-Based | YAML & Python | Medium | High-speed data centre automation and remote command execution. |
Ultimately, the best DevOps configuration management tool is the one that aligns with how you work. Ansible’s simplicity makes it a fantastic starting point for many. Puppet offers rock-solid control for established enterprises. And Chef and SaltStack provide deep customisation for teams with specific programming strengths.
If you’re looking to explore the wider world of automation, you might find our guide on other powerful DevOps automation tools useful.
Putting Configuration Management into Practice
Alright, theory is great, but let’s get our hands dirty. Seeing how DevOps configuration management actually works day-to-day is where the lightbulb really goes on. This isn’t just a list of steps; it’s a living, breathing workflow that brings a sense of calm and predictability to what can often be a chaotic process.
Let’s walk through a classic example: setting up a new web server from scratch. We’ll follow the entire journey to see how each stage builds on the last, creating a solid, automated pipeline.

Step 1: Establish a Single Source of Truth with Git
Everything, and I mean everything, begins with version control. Before a single line of configuration code is written, your first move is to make Git the undisputed single source of truth. This means setting up a dedicated repository where all your configuration files will be stored, managed, and versioned.
This isn’t just about good housekeeping. By doing this, you immediately create a complete, auditable history of every single change. Every firewall rule adjustment, every package update, every tweak to a user’s permissions it’s all tracked. This repository becomes the definitive blueprint for your entire infrastructure.
Step 2: Write Your Configuration Code
With your Git repository ready, it’s time to define the “desired state” of your server using code. This is where tools like Ansible, Puppet, or Chef step in. You’ll write a file perhaps an Ansible playbook or a Puppet manifest that describes exactly what your web server should look like when it’s done.
For our web server, this code might declare things like:
- Package Installation: The latest stable version of Nginx must be installed.
- Service Management: The Nginx service must be running and configured to launch on boot.
- File Configuration: A specific
nginx.conffile needs to be in/etc/nginx/to manage virtual hosts. - User Permissions: A dedicated
www-datauser account must exist with the correct permissions.
Notice the language here. You’re not writing a script of commands to run. You’re declaring the end state. The configuration tool is smart enough to figure out the steps needed to get there. This code becomes living, executable documentation for your systems.
Step 3: Test Configurations Rigorously
You wouldn’t dream of shipping application code without testing it first, right? The exact same discipline applies to your infrastructure code. A buggy configuration can be just as catastrophic as a buggy feature, leading to major outages. That’s why a staging environment isn’t optional it’s essential.
Before any configuration change gets anywhere near a production server, it needs to be validated in an isolated environment that’s a carbon copy of production. This is where you catch typos, check dependencies, and make sure the changes don’t have unintended side effects.
This step is your safety net. It’s what separates reliable, automated infrastructure from high-risk gambling. It prevents a simple mistake from taking down your entire service.
The move towards structured DevOps practices like this is paying off big time. Globally, around 77% of organisations have adopted DevOps to sharpen their deployment processes. In India, the results are even more striking: 50% of organisations using DevOps are considered elite or high-performers, showing just how much of a competitive edge this agility provides. You can dig into more data on how DevOps adoption creates high-performing teams on esparkinfo.com.
Step 4: Integrate into Your CI/CD Pipeline
The final piece of the puzzle is hooking your configuration management tool into your CI/CD (Continuous Integration/Continuous Deployment) pipeline. This is where the magic of full automation happens. A simple git push to the main branch can now trigger the entire deployment workflow without any manual intervention.
Here’s how it works in practice:
- An engineer pushes a change to the web server configuration in the Git repository.
- The CI/CD pipeline instantly detects this commit and kicks off a new job.
- The pipeline automatically applies the configuration to the staging environment and runs a battery of tests.
- If everything checks out, the pipeline gets the green light to apply the exact same configuration to the production servers.
This integration turns infrastructure management from a slow, manual chore into a fast, automated flow. It ensures changes are rolled out safely and consistently every single time, freeing up your team to focus on building great products, not babysitting servers.
Best Practices for Sustainable Automation
Getting a DevOps configuration management tool up and running is one thing. Building an automated system that actually stands the test of time? That’s a whole different ball game. Success comes down to adopting a few strategic habits that keep your systems scalable, secure, and collaborative. These are the hard-won principles that separate a smooth automation culture from a project doomed to fail.
Don’t make the mistake of trying to automate everything at once. The smartest way forward is to begin with a small, low-risk pilot project. This lets your team get comfortable with the tools, show some quick wins, and build momentum without putting critical business operations at risk.
Once you’ve proven the concept works, you can start expanding. A successful pilot creates the confidence and organisational support you need to roll it out more widely. If you’re looking at a full-scale deployment, our guide on crafting a DevOps implementation roadmap can give you a structured plan to follow.
Build Modular and Reusable Code
As your automated footprint grows, massive, monolithic configuration files quickly become a nightmare to manage. The secret to scaling gracefully is to write modular, reusable configuration code. Think of your configurations less like a single, giant sculpture and more like a set of Lego bricks.
Break your code down into smaller, self-contained components or roles. Each one should handle a single, specific job, like setting up a web server, configuring a database, or managing user accounts. This approach pays off in several ways:
- Reusability: A well-built “firewall” module can be used on hundreds of servers without ever copying and pasting code.
- Maintainability: When you need to update something like your NTP server settings, you edit one small, predictable file instead of digging through thousands of lines of code.
- Clarity: It’s far easier for a new team member to get their head around a small, focused module than a single, intimidating configuration file.
This kind of modularity is a cornerstone of modern infrastructure management. It turns overwhelmingly complex systems into a collection of simple, understandable parts.
Prioritise Infrastructure Testing
You wouldn’t ship application code without testing it, so why would you treat your infrastructure code any differently? You absolutely must implement robust testing for your infrastructure code. A simple configuration mistake can be just as destructive as a software bug, potentially taking down your entire service. Your production environment should never be your testing ground.
Infrastructure testing isn’t an optional extra; it’s your primary safety net. It confirms your configurations will work as intended before they get deployed, preventing expensive mistakes and building trust in your automation.
Effective testing means using staging environments that are a carbon copy of production. Specialised tools and frameworks now exist just for testing infrastructure code. They allow you to check that services start correctly, files are where they should be, and security rules are properly applied long before a change goes live.
Securely Manage Your Secrets
One of the most critical best practices in DevOps configuration management is to never store secrets in your version control system. Secrets are things like API keys, database passwords, and private certificates. Committing them to a Git repository is a massive, and all too common, security blunder.
Instead, use a dedicated secrets management tool like HashiCorp Vault or AWS Secrets Manager. These platforms store your sensitive information securely and let your configuration management tool fetch them on the fly at runtime. This practice creates a clean separation between your code and your credentials, giving you a secure and auditable way to handle secrets.
The results of adopting these mature DevOps practices are hard to ignore. For Indian IT firms, strong configuration management directly leads to better quality and faster delivery. In fact, research shows that 99% of organisations using DevOps report positive outcomes, with 61% pointing to improved product quality. What’s more, teams with a mature culture spend roughly 33% more time on infrastructure improvements, which translates to faster deployments. Nearly half (49%) see their delivery cycle times shrink a clear competitive edge. You can find more details on these DevOps trends and their impact on multiqos.com.
Common Questions About Configuration Management
As you start exploring DevOps configuration management, it’s perfectly normal for questions to pop up. You’re dealing with new tools, new ways of thinking, and different workflows, so getting a few things straight is crucial for building a solid foundation. We’ve pulled together some of the most frequent questions we hear to give you clear, practical answers.
Think of this as your quick-start guide for tackling those nagging “what if” and “how does” moments.
What Is the Difference Between Configuration Management and Orchestration?
This is a classic point of confusion, but a simple analogy makes it crystal clear. Picture a symphony orchestra.
Configuration management is like making sure every single instrument is perfectly tuned. It’s the process of ensuring the violins are in key, the trumpets are polished and working, and the drums have the right tension. The focus is squarely on the individual components. Tools like Ansible or Puppet are masters at this, ensuring a single server or service is configured just right.
Orchestration, on the other hand, is the conductor leading the whole orchestra to play a beautiful symphony. It’s all about making those perfectly tuned instruments work together in harmony. This is where tools like Kubernetes shine, managing how multiple containers, services, and servers interact to deliver a complex application.
In short, you use configuration management to build flawless, reliable components. You use orchestration to make those components perform a complex task together. They aren’t competing against each other; they are essential partners in any good automation strategy.
How Does Configuration Management Improve Security and Compliance?
Configuration management fundamentally shifts security from a manual, after-the-fact checklist to an automated, continuous process. It’s a game-changer for enforcing security policies across your entire infrastructure proactively, not reactively.
When you define your security rules as code things like firewall settings, user permissions, or required software patches you create a single, enforceable blueprint for what “secure” looks like. This is often called Policy as Code.
This coded blueprint gives you several powerful advantages:
- Continuous Enforcement: The configuration management tool constantly scans your systems against the defined security policy. If it spots an unauthorised change or “drift,” it can automatically fix it, pulling the system back into compliance.
- Auditable History: Since every configuration change is tracked in a version control system like Git, you have a transparent, iron-clad log of who changed what, when, and why. This makes proving compliance for audits like PCI DSS or HIPAA infinitely simpler.
- Scalable Security: Manually securing ten servers is a pain. Securing a thousand is nearly impossible. With configuration management, you apply the same secure baseline to every new server automatically, ensuring your security standards scale right alongside your infrastructure.
This approach transforms your security posture from a state of hopeful compliance to one of provable, automated enforcement.
Can I Use Configuration Management on My Existing Infrastructure?
Absolutely. You don’t need a brand-new, empty environment to get started. In fact, applying DevOps configuration management to existing, or “brownfield,” infrastructure is one of its most valuable uses. The trick is to avoid a “big bang” implementation.
The best strategy is to start small and build momentum. Don’t try to automate your entire data centre on day one. Instead, find a quick win.
Look for a repetitive, low-risk task that eats up your team’s time. Good candidates often include:
- Standardising NTP (Network Time Protocol) settings across all servers for consistent timekeeping.
- Managing user accounts and SSH keys to centralise and secure access control.
- Ensuring a standard set of monitoring agents is installed and running on every machine.
Automating just one of these small tasks delivers immediate value, helps your team get comfortable with the tools, and proves the power of the approach without risking critical operations. Many tools can even “discover” the current configuration of your servers to help you write your initial code. Once you’ve got a win under your belt, you can gradually expand your automation. To see how this fits into a broader strategy, you can explore how DevOps can be more than a buzzword to unleash business transformation. This incremental adoption is a proven path to success.