Zero downtime deployment is a simple but powerful idea: you can update your applications without ever taking them offline. It means no more late-night maintenance windows and ensures your software is always available, even as you’re pushing out new features or critical fixes. It’s about making your release process invisible to your users.
Why Downtime Is No Longer an Option
In today’s always-on digital economy, the whole concept of a “maintenance window” feels like a relic from a bygone era. For any modern business, service interruptions directly translate into lost revenue, a hit to customer trust, and a tarnished brand reputation. It’s not just a nice-to-have anymore; for competitive sectors like e-commerce, finance, and SaaS, continuous availability is the absolute baseline.
This is why achieving zero downtime deployment has shifted from a technical goal to a core business strategy. It’s what allows you to stay agile, keep your customers happy, and ultimately, grow your business.
The Business Impact of Service Interruptions
The financial fallout from outages is staggering. A survey involving Fortune 1000 companies, including some major Indian IT service providers, found that unplanned downtime costs businesses between $1.25 billion and $2.5 billion every single year. In India’s booming digital market, where industries like banking and retail are transforming at breakneck speed, the need for uninterrupted service has never been more critical. You can learn more about this journey towards uninterrupted software updates on InApp.com.
This massive financial risk alone makes a strong case for investing in modern deployment practices. But the cost isn’t just about money. The other consequences can be just as damaging:
- Damaged Customer Confidence: When users hit an error page or find your service down, they don’t wait around. They just go to a competitor.
- Reduced Developer Productivity: Instead of building valuable new features, your team ends up fighting fires during and after a messy deployment.
- Brand Erosion: Frequent downtime quickly chips away at the trust you’ve worked so hard to build, making it tougher to attract and keep customers.
The real goal here is to make your release process so smooth and reliable that it becomes a complete non-event for your users. You’re transforming deployments from a major source of risk into a routine, predictable part of business.
This chart really drives home the tangible improvements teams see after they make the switch to zero downtime methods.
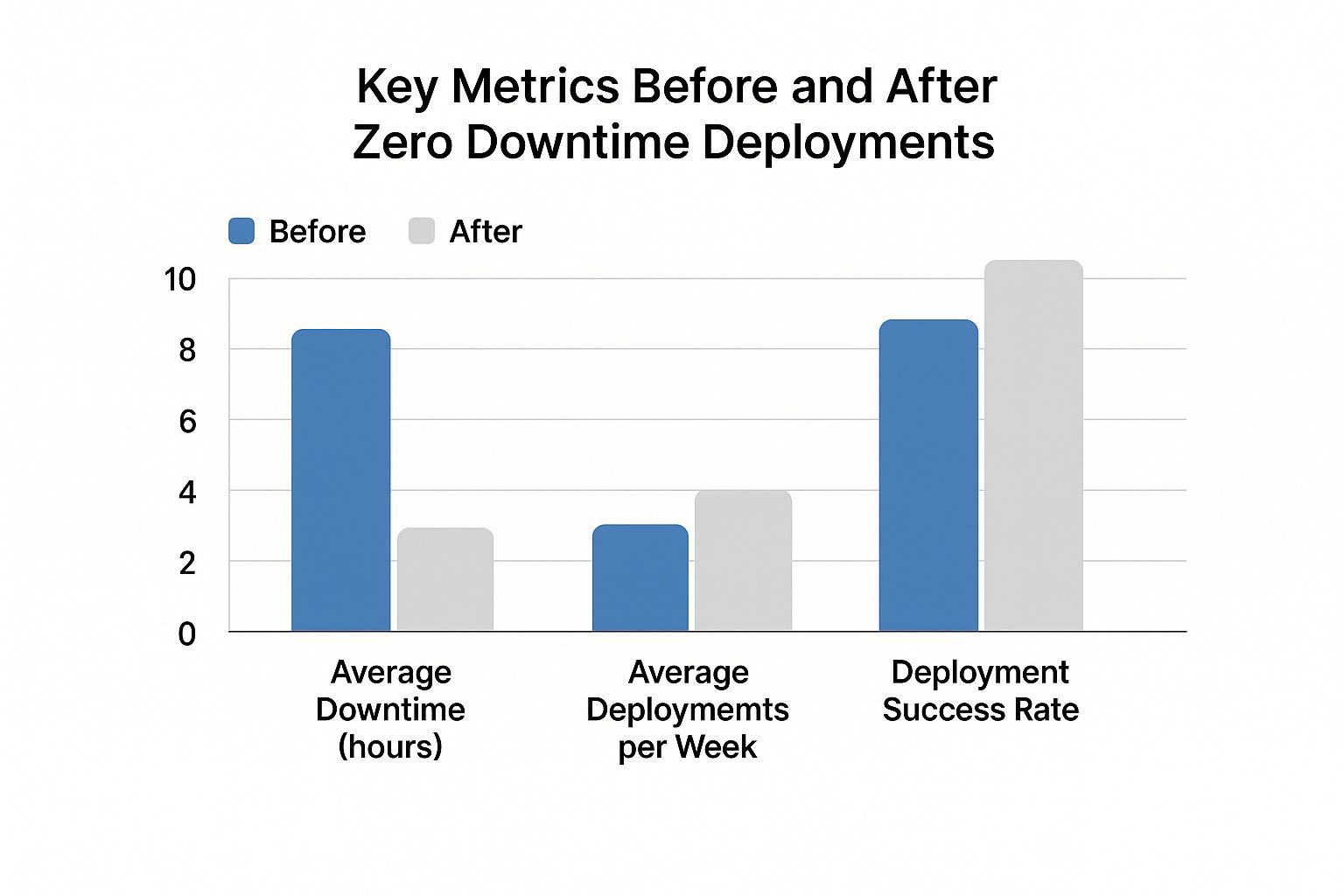
The data speaks for itself. Adopting modern deployment practices doesn’t just cut down on outages it empowers your teams to ship better software, faster and more reliably than ever before.
Deployment Strategy At-a-Glance
To help you get your bearings, it’s useful to see the main strategies side-by-side. Each has its own strengths and is suited for different scenarios.
| Strategy | Core Concept | Ideal Use Case | Risk Level |
|---|---|---|---|
| Blue-Green | Two identical production environments. Traffic is switched instantly from the old (Blue) to the new (Green). | When you need a fast, simple rollback and can tolerate the cost of duplicate infrastructure. | Low |
| Rolling Update | The application is updated instance-by-instance until the entire fleet is running the new version. | Applications with multiple instances where a gradual rollout is acceptable. | Medium |
| Canary Release | The new version is released to a small subset of users first, then gradually rolled out to everyone. | When you want to test a new feature with real traffic before a full release, minimising risk. | Low to Medium |
Think of this table as a quick reference. As we dive deeper into each method, you’ll get a much clearer picture of how they work and which one is the right fit for your specific needs.
Using Rolling Updates for Simple Releases

When you’re first dipping your toes into the world of zero downtime deployment, rolling updates are often the best place to start. They’re a practical and effective way to get the job done. Instead of a risky, all-at-once switch, this method gradually replaces old versions of your application with the new one, either instance-by-instance or in small batches. This methodical approach is what keeps your application online and serving users throughout the entire release process.
Think of an e-commerce platform running on ten servers behind a load balancer. A traditional deployment would mean taking all ten offline, creating a service blackout. A rolling update, on the other hand, might just pull one server from the load balancer, update it, run a quick health check, and only once it passes, add it back into the mix. Then, it moves on to the next one. Simple, yet powerful.
This strategy is particularly favoured across the Indian IT sector, where service continuity is paramount. Many Indian tech companies have embraced rolling updates because they offer a reliable path to a smooth user experience without the drama of a full outage. Typically, they’ll update a small portion of their server fleet, say 10-20%, at any given moment, while the rest of the instances handle live traffic without a hitch.
Getting Your Rolling Update Configuration Right
The real craft of a rolling update isn’t in the concept, but in the configuration. While platforms like AWS Elastic Beanstalk, Amazon ECS, or Kubernetes have built-in support for this, a successful deployment hinges on fine-tuning the right parameters. You’re constantly balancing the need for speed with the need for safety.
One of the first decisions you’ll make is the batch size. In our e-commerce example, updating two servers at a time (a batch size of 20%) gets the deployment done faster than updating one by one. However, it also introduces a slightly higher risk if something goes wrong. This is a classic trade-off that your team needs to decide on, based on your application’s architecture and how much risk you’re comfortable with.
Just as important is defining what a “healthy” new instance actually looks like. This is where your health checks come into play. A basic check might just ping the server for a 200 OK response. But for a truly resilient system, you need more. A robust health check should hit a dedicated /health endpoint that confirms critical dependencies, like database connections, are working perfectly before the new instance is allowed to take live traffic.
Key Takeaway: The secret sauce for a bulletproof rolling update is pairing it with automated rollbacks. If your monitoring detects an error spike or a performance dip right after a new batch goes live, the system should be smart enough to automatically revert to the previous stable version. No late-night calls, no manual intervention needed.
Practical Tips for a Smooth Implementation
To make your rolling updates feel less like a gamble and more like a routine, here are a few things I’ve learned to always keep in mind.
- Master
maxUnavailableandmaxSurge: If you’re working in Kubernetes, these two settings are your best friends.maxUnavailabledictates the maximum number of instances that can be offline during the update, whilemaxSurgelets you temporarily create new instances above your target count. Using them together ensures your application capacity never drops dangerously low. - Don’t Forget Connection Draining: Make sure your load balancer is configured to handle existing user sessions gracefully. When an instance is scheduled for an update, connection draining allows it to finish serving any active requests before it’s taken out of rotation. This simple setting prevents users from getting a frustrating, abrupt disconnection.
- Make it an Automated Part of Your Pipeline: A rolling update shouldn’t be a manual, nerve-wracking event. It should be a standard, predictable stage in your CI/CD pipeline. To see how this fits into the broader DevOps workflow, take a look at our guide to automated software deployment.
By getting these details right, you can turn the simple concept of a rolling update into a powerful and reliable engine for achieving zero downtime deployments.
Implementing Blue-Green Deployment for High-Stakes Systems

When you’re running systems where even a flicker of downtime is a major problem, blue-green deployment isn’t just a good idea it’s often the best strategy you have. The concept is straightforward but incredibly effective: you maintain two identical production environments. We call one ‘blue’ and the other ‘green’.
At any given time, only one of them is live. Let’s say ‘blue’ is currently handling all your user traffic. The ‘green’ environment is its perfect clone, sitting idle and ready for the next update. This dual-environment setup is the key to achieving zero downtime. You can push your new application version to the green environment, which is completely isolated from live traffic. This gives your team a safe space to run every test imaginable integration, performance, security on a production-spec system without affecting a single user.
Think about a high-stakes financial services app. Transactions have to be processed perfectly, 24/7. With a blue-green approach, you could roll out a massive update to the green environment in the middle of a business day. Your team gets to hammer it, testing every single feature from fund transfers to statement generation, all while the live blue environment continues to operate flawlessly. You only make the switch when you’re certain everything is perfect.
Preparing the Green Environment
First things first, you need to bring your green environment up to speed. This goes far beyond just spinning up a few servers. It has to be a mirror image of your live blue setup.
This means ensuring:
- Identical Infrastructure: You need the same server specs, load balancers, and network configurations. Any deviation can introduce unexpected variables.
- New Application Code: The new version of your application gets deployed here, and only here.
- Matching Dependencies: All backing services, external APIs, and database connections must be configured just like they are in production.
Once the green environment is running the new code, the real work begins: testing. This is your moment to be thorough. Run your automated test suites to check functionality, and have your monitoring tools watch performance metrics like latency and CPU usage closely. The objective is simple: be 100% confident in the new release before it goes live.
Pro Tip: I’ve seen teams make the mistake of testing the green environment in a vacuum. For a truly reliable test, it must connect to the same live production databases and external services that the blue environment uses. This is how you catch those tricky configuration or permission issues that only surface under real-world conditions.
Executing the Traffic Switch
After rigorous testing gives you the green light, it’s time to make the switch. Honestly, this is the most satisfying part. With a quick configuration change at the router or load balancer, you instantly reroute all incoming user traffic from the blue environment to the green one.
For your users, the change is instantaneous and completely invisible. One moment they’re on the old version, the next they’re seamlessly using the new, improved application. Meanwhile, the old blue environment remains on standby. If something unexpected happens, you have an immediate rollback plan. Just flip the switch back. It provides a safety net that is hard to beat.
Tackling Database and State Management
The trickiest part of any blue-green deployment is managing state, especially when you have database schema changes. It’s the one piece that both environments often need to share. A solid strategy here is to ensure any database changes are backward-compatible.
This means the new code in the green environment can work with the old schema, and just as importantly, the old code in the blue environment won’t break when it encounters the new schema. For example, if you need to add a new column to a table, you would design it to be nullable. This way, the old application code, which knows nothing about this new column, can still write new rows without failing. This approach lets both environments share the same database during the transition, paving the way for a truly seamless deployment.
Canary Releases: A Data-Driven Approach to Rollouts
While rolling updates and blue-green deployments get the job done for zero downtime, canary releases add a crucial layer of intelligence: real-world data. This strategy turns your deployment into a live, controlled experiment. Instead of going all-in, you release the new version to a small, specific subset of your users the proverbial “canaries in a coal mine”.
The whole idea is to gather performance and user behaviour data from live traffic before committing to a full rollout. If your canaries show any signs of trouble, you can pull the plug and roll back the change instantly. The beauty of this is that only a tiny fraction of your user base is ever affected, drastically lowering the risk that comes with shipping new features or big architectural shifts.
First, Define What “Good” Looks Like
A canary release is only as useful as the metrics you track. Before you even think about routing traffic, you need to be crystal clear about what success actually means for this new version. Just checking for crashes won’t cut it. You need a balanced view across several key performance indicators (KPIs).
Your monitoring dashboard should be focused on a few critical areas:
- System Performance: Keep a close eye on application error rates, response latency, and resource usage like CPU and memory. A sudden spike in any of these metrics for the canary group is a massive red flag.
- User Engagement: Are people in the canary group actually using the new feature as you hoped? You should be tracking business-level metrics like conversion rates, click-throughs, or average session duration.
- Infrastructure Health: Don’t forget the underlying instances. Make sure the servers running the canary version are stable and aren’t showing signs of stress that could blow up once you send more traffic their way.
This constant feedback loop is what makes the canary strategy so effective. It shifts your confidence from “we think it works” to “we know it works” because you have the evidence to back it up.
The real power of a canary release isn’t just catching catastrophic failures. It’s about spotting those subtle performance dips that would otherwise go unnoticed until they’re impacting every single one of your users.
How to Split Traffic in the Real World
Pulling off a canary release means you need surgical control over your traffic routing. Thankfully, modern tools like service meshes and other cloud-native technologies are built for this exact purpose.
For example, with a service mesh like Istio or AWS App Mesh, you can set up incredibly specific traffic-splitting rules. A common approach is to start small. Route just 1% of your production traffic to the new version. Your monitoring tools will then analyse this canary group’s performance in real-time.
If all your metrics look healthy, you can start dialling it up. Maybe you increase the traffic to 5%, then 25%, and continue incrementally until 100% of your users are on the new, proven version.
This gradual, evidence-based process is a cornerstone of building truly resilient systems. The ability to safely test changes under live conditions is a fundamental part of achieving high availability. To learn more about building robust infrastructure, you can explore our guide on understanding fault tolerance in cloud computing. When you combine canary releases with a fault-tolerant architecture, you create a system that’s not just always on, but one that gets better and better with minimal risk.
Building an Architecture That Enables Seamless Deployments

A slick CI/CD pipeline is a great start, but it’s only half the story. The truth is, your ability to achieve zero downtime is baked right into your system’s architecture. Even the most sophisticated deployment scripts will hit a brick wall against a rigid, monolithic design that demands an all-or-nothing update.
This is where your architectural choices become your secret weapon. The decisions you make early on have a direct, and massive, impact on your operational agility and whether you can deploy without causing a single blip in service. It’s about building for change from the very beginning.
The shift towards microservices architecture has been a game-changer for this very reason. By breaking down massive applications, teams can update small, independent pieces without taking the entire system offline. This modular approach is fundamental to deploying with confidence.
Structuring Your Application for Independence
Think of microservices as breaking a huge application into a collection of smaller, self-contained services. Each one handles a distinct business function maybe one manages user authentication, another handles the product catalogue, and a third processes payments. This separation is what makes seamless updates possible.
When you need to patch the payment service, you can deploy a new version of just that service. The user authentication and product catalogue services? They carry on, completely unaware and uninterrupted. This decoupling gives your teams the autonomy to release updates on their own schedules, which is a massive leap from the old ways. To get this right, you need a solid foundation built on proven cloud architecture design principles.
Managing Databases Without Downtime
Database changes are notoriously tricky and often the biggest culprit behind unexpected downtime. A clumsy schema migration can lock up tables, bringing your application to a dead stop. The trick is to approach database changes in phases, ensuring your system can handle both the old and new versions simultaneously.
Here are a few techniques I’ve seen work wonders:
- Additive Changes First: Instead of modifying or deleting a column right away, add the new one first. Your old code simply ignores it, while the newly deployed version can start writing to it.
- The Expand-Contract Pattern: This is a multi-step dance. You first expand the system to support both the old and new schemas, migrate your traffic and data over, and only then do you contract by removing the old, now-unused structures.
- Avoid Locking Tables: Use modern database tools and migration frameworks that are smart enough to alter schemas without locking the entire table from read/write operations. There’s often no need to halt everything if you use the right approach.
My Two Cents: Feature flags are the perfect partner for a well-designed architecture. They let you separate the deployment of code from the release of a feature. You can push new code to production with the feature safely turned off, then flip the switch for specific users or a percentage of traffic whenever you’re ready—all without another deployment cycle.
When you combine a smart architecture with careful database management and feature flags, deployments stop being a source of anxiety. They become a safe, routine part of your daily operations.
Common Questions About Zero Downtime Deployment
When teams start exploring zero downtime deployment, a few common questions and roadblocks always seem to pop up. It’s one thing to get your head around the theory, but putting it into practice in a live production environment is a completely different ball game. Let’s dig into some of those frequently asked questions with some advice straight from the trenches.
What Is the Biggest Challenge?
Hands down, the single biggest hurdle isn’t the tooling or the CI/CD pipeline. It’s managing state.
Most applications aren’t stateless. They have databases, user sessions, and caches that need to stay consistent right through a deployment. This gets especially tricky when a new release needs to alter the database schema.
If you just push the new code, you can easily end up in a situation where the updated application code can’t work with the old database schema, or the other way around. That almost always leads to an outage. Getting past this means you have to think differently you’re not just deploying code anymore, you’re carefully managing the entire application’s state through a delicate transition.
The real aim is to make database changes completely non-breaking. This often involves breaking down one big, risky migration into several smaller, phased updates that are deployed separately. This way, both the old and new versions of your code can live happily with the database schema while the deployment is happening.
How Should We Handle Database Schema Changes?
This question naturally follows the first, because it’s precisely where many zero downtime plans fall apart. The secret is to separate your database schema changes from your application deployments. You need a game plan that lets both the old and new versions of your app run smoothly with the database during the entire update.
A battle-tested approach for this is the expand and contract pattern. Here’s how it works:
- Expand (The Additive Phase): First, you deploy changes that only add new things. Think about adding a new column to a table, but you make it nullable. This means the old code, which knows nothing about this column, can still write new rows without causing an error. Your new code can start using it straight away.
- Migrate (The Transitional Phase): Once the new code is fully rolled out and stable, you can run scripts to backfill the data for your new column or migrate existing data over.
- Contract (The Cleanup Phase): After you’re confident everything is working and a safe amount of time has passed, you can deploy another change to clean up and remove the old, unused columns or tables.
This methodical, multi-step process ensures your database is never in a state that could break either version of your application.
Which Strategy Is Best for a Startup?
For a startup or a small team where resources are tight, the rolling update strategy is usually the most practical and budget-friendly place to start. It avoids the need to double up your infrastructure costs, which is what a full blue-green deployment demands. For an early-stage company, that cost can be a serious issue.
Modern platforms like Kubernetes and managed services such as AWS Elastic Beanstalk provide rolling updates as a standard, well-supported feature. This gives a small team a straightforward path to achieving basic zero downtime without immediately needing to wrestle with complex service meshes or sophisticated traffic management tools. It offers the most significant improvement for the least amount of operational effort.
At Signiance Technologies, we specialise in designing and implementing robust cloud and DevOps solutions that make zero downtime a reality. Our experts can help you build secure, scalable, and resilient infrastructures. Transform your deployment pipeline by visiting us at https://signiance.com.